Node.js : Day 3
15 days Challenge

Client-Server Architecture:

What happens when we access a webpage?

Step 1. DNS Lookup
What happens:
The browser or client application initiates a request to resolve the human-readable domain name (e.g., www.google.com) into an IP address, which is necessary for routing the request.
Why it’s needed
The DNS (Domain Name System) translates domain names into IP addresses, allowing devices to find each other over the internet.
2. TCP/IP Socket Connection
What happens
After resolving the IP address, the browser establishes a TCP (Transmission Control Protocol) connection with the web server at that IP address. This is done via the IP protocol, typically using port 80 for HTTP or port 443 for HTTPS.
Why it’s needed
This connection allows the client and server to exchange data reliably over the network.
3. HTTP Request
What happens
- The browser sends an HTTP request to the server for the specific resource (e.g., a webpage). The request typically uses the
GETmethod, though other methods likePOSTmay be used for sending data (like forms).
Structure of the request:

- Start line: This includes the HTTP method (
GET,POST, etc.), the requested resource (e.g.,/maps), and the HTTP version (HTTP/1.1). - Headers: These provide metadata about the request, such as the client’s capabilities (via
User-Agent), accepted languages (Accept-Language), and other headers like cookies or authentication tokens. - Body: In
GETrequests, there usually isn't a body, but inPOSTorPUTrequests, there might be a body that contains data to send to the server (e.g., form submissions).
4. HTTP Response
- What happens: The server processes the request and sends back an HTTP response, which indicates whether the request was successful or not, and includes the requested content (such as an HTML page).
- Structure of the response:

- Start line: This contains the HTTP version (e.g.,
HTTP/1.1), a status code (e.g.,200 OKfor success or404 Not Foundfor an error), and a status message. - Headers: These contain metadata about the response, such as content type (
Content-Type: text/html), caching policies, and cookies. - Body: This is where the content resides, such as HTML code, CSS, JavaScript, images, etc.
5. Loading Files
- The browser first loads the main HTML file.
- Then, it sequentially loads any additional resources referenced in the HTML (like CSS for styling, JavaScript for interactivity, images, etc.).
- Each of these resources typically triggers a separate HTTP request to the server, and the corresponding responses are returned.
Summary of the Flow:
- DNS Lookup: Resolves domain name to IP.
- TCP/IP Connection: Establishes communication with the server.
- HTTP Request: The browser requests a resource from the server.
- HTTP Response: The server sends back the requested resource.
- Loading Files: The browser loads and processes assets like HTML, CSS, JS, and images to display the webpage.
Node.js Architecture:
The architecture of Node.js is designed to handle asynchronous operations and enable efficient event-driven programming. Here’s a detailed breakdown of how it works, based on the key components:
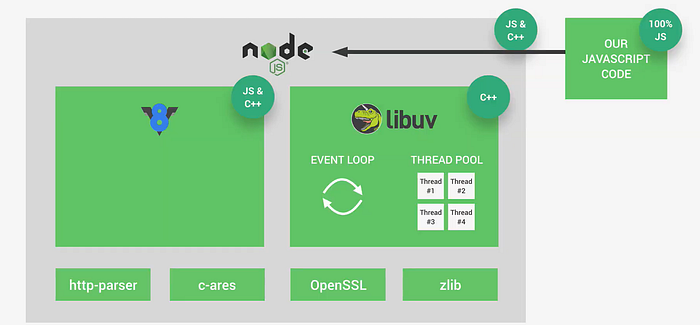
V8 Engine :
- Developed by Google, V8 is a highly efficient JavaScript engine used by Node.js to execute the JavaScript code. It compiles JavaScript to machine code for faster execution.
- Written in C++ and JavaScript: The engine itself is written in C++ to interact directly with the underlying system, providing performance benefits.
- Role in Node.js: V8 serves as the foundation for executing the JavaScript code. It’s responsible for parsing and executing the JS code that the developer has written. Every function, variable, and object created in your JavaScript code is processed by the V8 engine.
libuv:
- libuv is a C++ library that enables Node.js to handle asynchronous I/O operations in a non-blocking manner. It’s a crucial component of the Node.js architecture, responsible for the event-driven model.
Key Components of libuv:
Event Loop:
- The event loop is at the heart of Node.js’s asynchronous architecture. It allows Node.js to handle multiple operations (such as HTTP requests or reading from a file) without blocking the execution of other tasks. The event loop listens for events and executes callbacks associated with those events.
Thread Pool:
- libuv maintains a thread pool (with multiple threads, e.g., Thread #1 to Thread #4) to execute tasks that require CPU-intensive operations (like file I/O, DNS resolution, and other blocking tasks). These tasks are moved to the thread pool to prevent blocking the event loop.
Non-blocking I/O:
- libuv allows Node.js to handle multiple I/O operations concurrently, making it very efficient in handling high-throughput applications, like web servers.
Supporting Libraries:
- Node.js relies on several core libraries to handle specific system tasks efficiently. These libraries are implemented in C++ to provide low-level functionalities:
- http-parser: This library is responsible for parsing HTTP requests and responses. When a client sends an HTTP request, the
http-parserinterprets the message so that Node.js can process it correctly. - c-ares: Handles DNS (Domain Name System) resolution, allowing Node.js to translate domain names (like
google.com) into IP addresses for making network requests. - OpenSSL: Ensures secure communication via SSL/TLS encryption. OpenSSL allows Node.js to handle encrypted connections, making it secure for web applications (e.g., HTTPS).
- zlib: Provides compression functionality. Node.js uses zlib for compressing and decompressing data, which is particularly useful when handling large files or transferring data over the network.
Summary of Node.js Works:
Node.js is an event-driven, non-blocking I/O model designed to handle concurrent operations efficiently. Here’s how it works:
- Developer’s JavaScript code is executed by the V8 engine.
- libuv handles the asynchronous operations by managing the event loop and delegating CPU-bound tasks to the Thread Pool.
- Node.js relies on C++ libraries (like http-parser, c-ares, OpenSSL, and zlib) to handle specific functionalities like HTTP parsing, DNS resolution, security, and compression.
- The event loop allows Node.js to process many requests concurrently without blocking, making it ideal for real-time applications, API servers, and I/O-heavy applications.
In this architecture, Node.js bridges the gap between JavaScript and low-level system operations, offering high performance and scalability for web servers and other networked applications.
Thanks…
